How Google's Open Knowledge Format validates the BuildOS knowledge layer I built by hand
I spent months hand-rolling a knowledge layer for my AI agent stack. Google just shipped a format that formalizes the exact same pattern. Markdown files, YAML frontmatter, cross-linked docs. Here is why that matters for anyone building with agents.
A few weeks ago I published a long piece on the foundational AI infrastructure stack I've been building over the past year. I called the whole shape BuildOS. The always-on server, the persistent agent in a tmux session, GitHub as the home for everything, MCP underneath, voice on every device.
I spent a good chunk of that article on a question that sounds small but turns out to be central: how does the agent know things? CLAUDE.md for the rules and priorities. A pointer pattern that keeps CLAUDE.md lean and sends the agent to docs/architecture.md or docs/deploy-runbook.md only when the task calls for it. Auto-memory for what the agent infers on its own. And one thing I noted in passing: auto-memory lives on the server's local filesystem, never lands in Git, and dies if the box dies. My workaround was to keep memory files to a few lines and let the real knowledge live in committed docs, so the agent can rebuild from the repo.
That workaround works. But the knowledge in those docs has no agreed shape. Each file is whatever I happened to write that day, in whatever structure made sense at the time. My agent reads them fine because it shares my conventions. Now hand the same repo to a different agent. The conventions don't travel. You end up re-explaining your project structure to every new model you try.
Google just shipped the answer to that. It's called the Open Knowledge Format (OKF for short), and if you have been doing any version of what I described in the BuildOS piece, you should pay attention to this one!
What OKF actually is
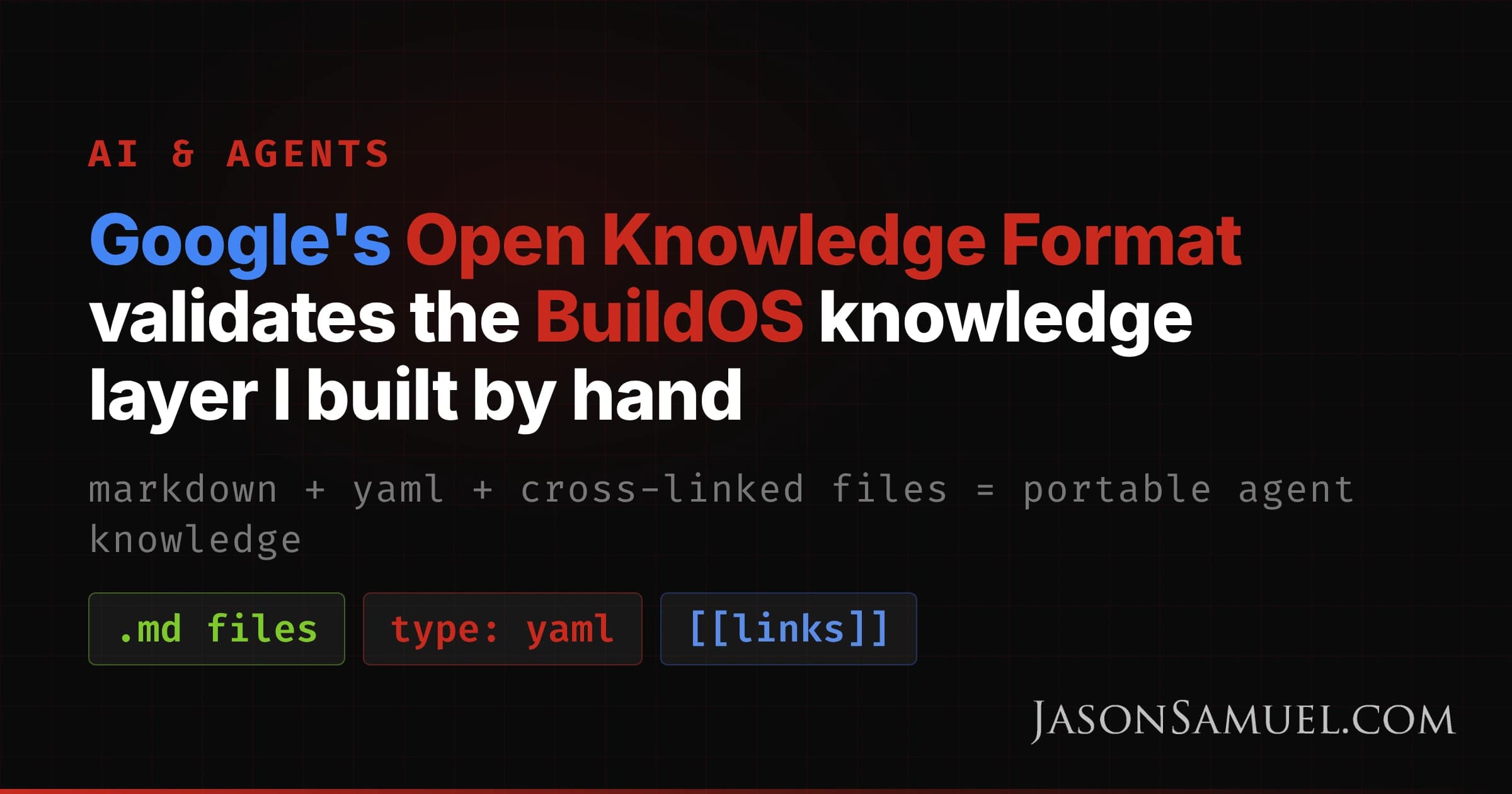
Here's the short version. An OKF bundle is a directory of markdown files. Each file is one concept: a table, a dataset, a metric, a runbook, an API, anything you want the agent to know. Concept files carry a small block of YAML frontmatter for the fields that need to be queryable, and the format requires exactly one field: type. Everything else is up to you. Concepts link to each other with ordinary markdown links, which turns the directory into a graph the agent can walk.
There are two reserved filenames worth knowing: index.md serves as the entry point for each directory (no frontmatter, just a listing that lets the agent drill down only when it needs to), and log.md for change history (newest entries first). If you have been using CONTINUATION.md and HISTORY.md the way I described in the BuildOS piece, you will immediately recognize what log.md is doing. Same instinct, formalized.

That's it! No SDK, no runtime, no account, no proprietary catalog service. Just markdown, just files, just enough YAML to make the structured fields searchable. If you have ever used Obsidian or written a CLAUDE.md, you already know what this looks like.
Andrej Karpathy described the underlying idea as an LLM wiki: a markdown library the agent reads and keeps current, where the cross-reference bookkeeping that makes humans abandon personal wikis is exactly the kind of work an agent is good at. You can see the same instinct in AGENTS.md and CLAUDE.md convention files. If you have a repo full of docs your agent consults before doing real work, you have already been living here. What was missing was agreement on the handful of conventions that let one team's knowledge be read by a different team's agent. OKF is that agreement.
How it maps to the BuildOS stack
Go back to the BuildOS piece and OKF lines up against it almost one for one.
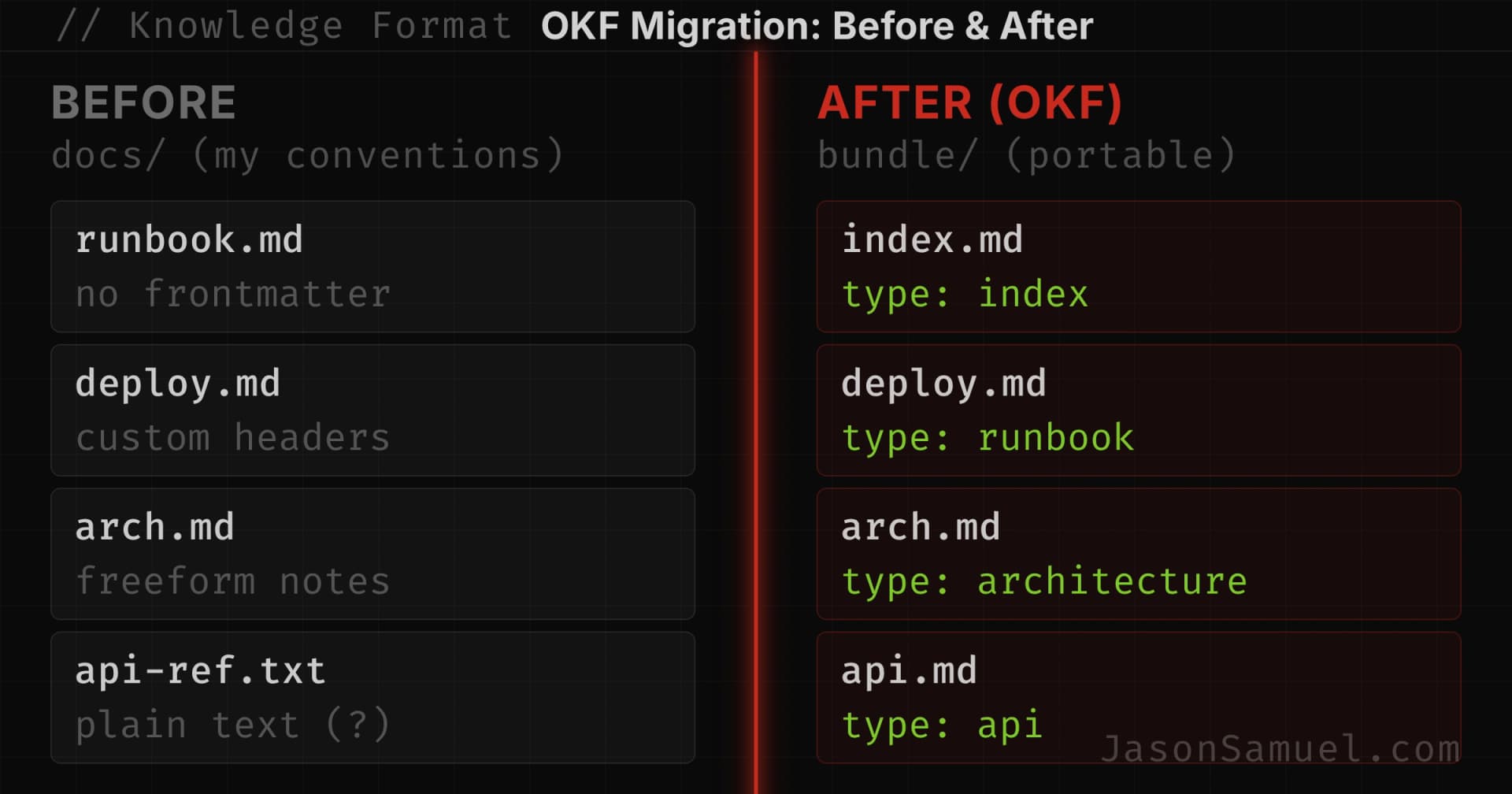
The pointer pattern gets a spec. In my experience, keeping CLAUDE.md small and pointing at longer docs marked "read on demand" is one of the most useful patterns for keeping the agent's core context clean. OKF builds that right in. The index.md convention is the pointer pattern written down, and the idea that the agent only pulls a doc when the task calls for it is baked into how you are supposed to structure a bundle. So you stop maintaining the habit by willpower and inherit it from the format. That alone is worth it!
The auto-memory gotcha gets resolved. This is the cleanest fit and I got genuinely excited when I saw it! I already said the canonical knowledge should live in committed docs so the agent can rebuild from the repo. OKF is the shape those docs were always supposed to have, in my opinion. The rebuild stops being "my agent reads some markdown I happened to structure a certain way" and becomes "any agent reads a standard bundle." In my current design the server burning down costs me very little (you lose the auto-memory convenience layer, but everything that matters is in Git). With OKF, switching the agent or the model costs you nothing either!
Now here is where it gets interesting for anyone running multiple projects. Right now my agent sees across projects because they share a parent folder and it reads what is in front of it. A single OKF bundle spanning the work turns that into something it can follow by relationship instead of by proximity. The cross-references I currently hold in my head become edges the agent follows on its own. If you are running several projects off one server, that is the difference between re-establishing context each session and having it sitting there as a map.
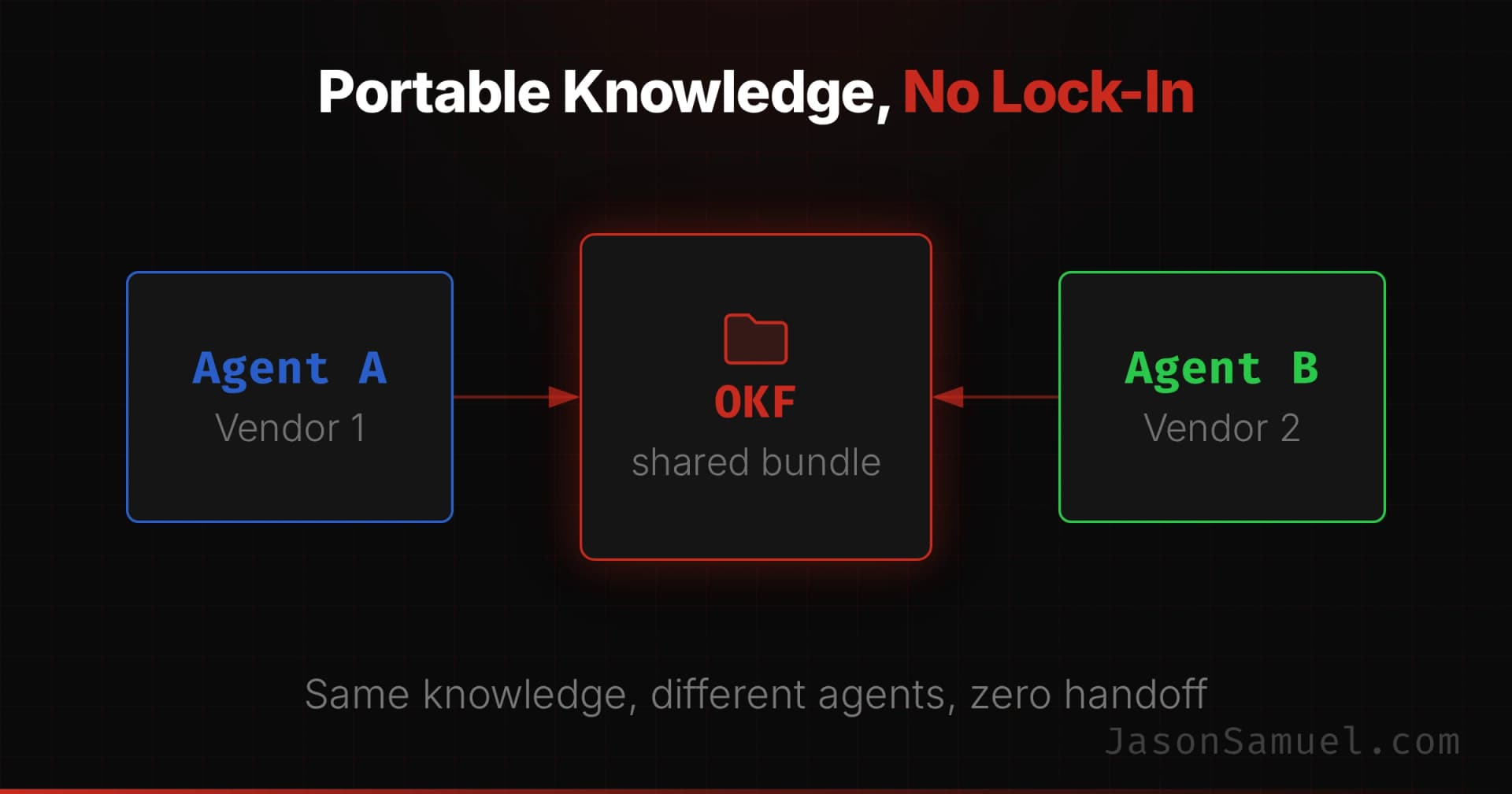
So what about the multi-agent future? In the A2A section of the BuildOS piece I described where this is heading: a primary agent handing a subtask to a specialized agent at a different vendor. A2A is how agents will pass work to each other. OKF is how they will share what they know while doing it. An agent from one vendor and an agent from another reading the same bundle? That is long-term memory shared across bodies, with no custom handoff!
So where does this leave the protocol stack?
In my opinion, the protocol story is coming together. One protocol for tools (MCP, which I use daily), one for agents (A2A, which I am watching closely), and now a format for what they all need to know (OKF).

Google also wired its own Knowledge Catalog to ingest OKF and serve it to agents, and shipped reference implementations and sample bundles in the open. All three are open standards, and that is exactly what you want to see here.
What I actually think
OKF doesn't add a new layer to BuildOS. It standardizes the knowledge layer I already built by hand and described at length in the original piece. In my experience, that is the highest praise you can give a new format: it names and formalizes something you had already converged on independently (badly, in isolation).
Two caveats. This is v0.1, and the team says so plainly. It will change as more people start using it and we figure out what agents actually need to know. And I haven't rebuilt my own bundles on it yet. I'm writing this the week it shipped, the way I flagged A2A as something I was watching rather than running. What I can say is that the design fits the stack so cleanly that I expect to be migrating my committed docs to it shortly, and I will write the follow-up with the lessons once I have them.
The repo and the spec are public. The spec is short. Read it, point a producer at one of your own systems, and see whether the bundle survives leaving your machine. That last part is the whole game!
I have to say it. I have never seen a stretch like the one we are in right now. MCP, A2A, OKF, the models getting better every month, the tooling catching up, the open standards landing one after another. You can feel it all coming together. And the best part is not just watching it happen from the sidelines. It is being in the middle of it, building with it every single day, seeing firsthand how practical all of this actually is. This is genuinely one of the most fun and exciting times I have experienced in my entire career. If you are building with agents right now, you already know what I mean!

Jason Samuel
Product leader, advisor, and international speaker with 27+ years in enterprise end-user computing, security, and cloud. Has deployed infrastructure at Fortune 500 scale across 38 countries. 1 of 3 people globally to hold Citrix CTP + VMware vExpert + VMware EUC Champion concurrently. 220+ articles, 1,000+ reader discussions.
Context rot is real. Your AI coding assistant gets dumber the longer you use it. Here is the structural fix.
AI coding assistants degrade mid-session and nobody warns you. The degradation is architectural, not motivational. Telling it to try harder does nothing. Here is the enforcement system that makes garbage structurally impossible.
ai-agentsYour AI agent is lying about being done. Here's the 4-part loop based proof system that makes faking impossible.
Hand an AI agent a codebase and tell it to fix things, and it'll happily report back that everything is done. The hard part isn't getting an agent to work autonomously. It's getting one that can't fool you into thinking it finished when it didn't.
ai-agentsBuild at the speed of thought: the complete AI infrastructure guide for non-developers
I've been telling people for the last year that AI lets you build at the speed of thought. I mean that literally, not as a marketing line. Whatever idea pops into your head, you can have a working version of it in an evening. Not a prototype. A working version. The catch is that it doesn't matter how smart the AI gets if your setup is wrong.