Your AI agent is lying about being done. Here's the 4-part loop based proof system that makes faking impossible.
Hand an AI agent a codebase and tell it to fix things, and it'll happily report back that everything is done. The hard part isn't getting an agent to work autonomously. It's getting one that can't fool you into thinking it finished when it didn't.

I've run into this so many times now that I've lost count. You hand an autonomous coding agent a task, it runs, it iterates, it reports "done," and you trust it. Then you look at the output and realize it passed itself on work that doesn't actually function. Not because the agent is broken. Because nothing in the loop forced it to prove anything.
This is a replicable pattern that fixes that, with code you can drop into any setup. It applies to any agent loop on any project: web apps, data pipelines, infrastructure, libraries. The pattern is tool-agnostic, but I'll show it through Claude Code's hooks system because that's where the enforcement gets interesting.

Why agents hand back false "done"
In my experience, an autonomous agent left to verify its own work tends to pass itself, for the same reason a student grading their own exam tends to pass. The failure is rarely laziness. It's that every check shares the author's blind spot.
Self-review (the agent reviewing its own output, even as multiple "personas") inherits the same misunderstandings that produced the bug. It doesn't matter how many times you ask it to re-check or how many "expert reviewer" personas you spin up. The underlying model is the same, and it has the same gaps.
Static checks (type checkers, linters) can't see inside opaque values. A query, a template string, a config blob is valid syntax no matter how wrong its contents. tsc --noEmit passing means the types are consistent. It doesn't mean the code does what you think it does.
A green test suite means nothing if the tests don't exercise the new code. "All tests pass" and "the new code was never actually run" coexist comfortably. I've seen this happen more times than I can count, especially when the agent writes both the fix and the test at the same time.
The agent's own claim of completion is unverifiable by definition. It's the thing under test certifying itself.
Every layer that gives a false pass has one thing in common: it inspects rather than executes, or it lets the author judge their own work.

The two principles
Both are required. Either alone is insufficient.
Execution beats inspection. Verify by running the code against realistic inputs and asserting on real outputs. Not by reading it, however many times or by however many reviewers. A bug that only appears at runtime is invisible to inspection and obvious to execution.
The judge can't be the author. The thing that decides "done" must be independent of the thing that wrote the code: a separate process, a real datastore, an external sandbox. Something that doesn't inherit the agent's assumptions.
Combine them and you get the core move: the finish line is an objective, executable test that the agent is structurally forbidden from editing. The agent can iterate freely on the implementation. It cannot touch the definition of success.
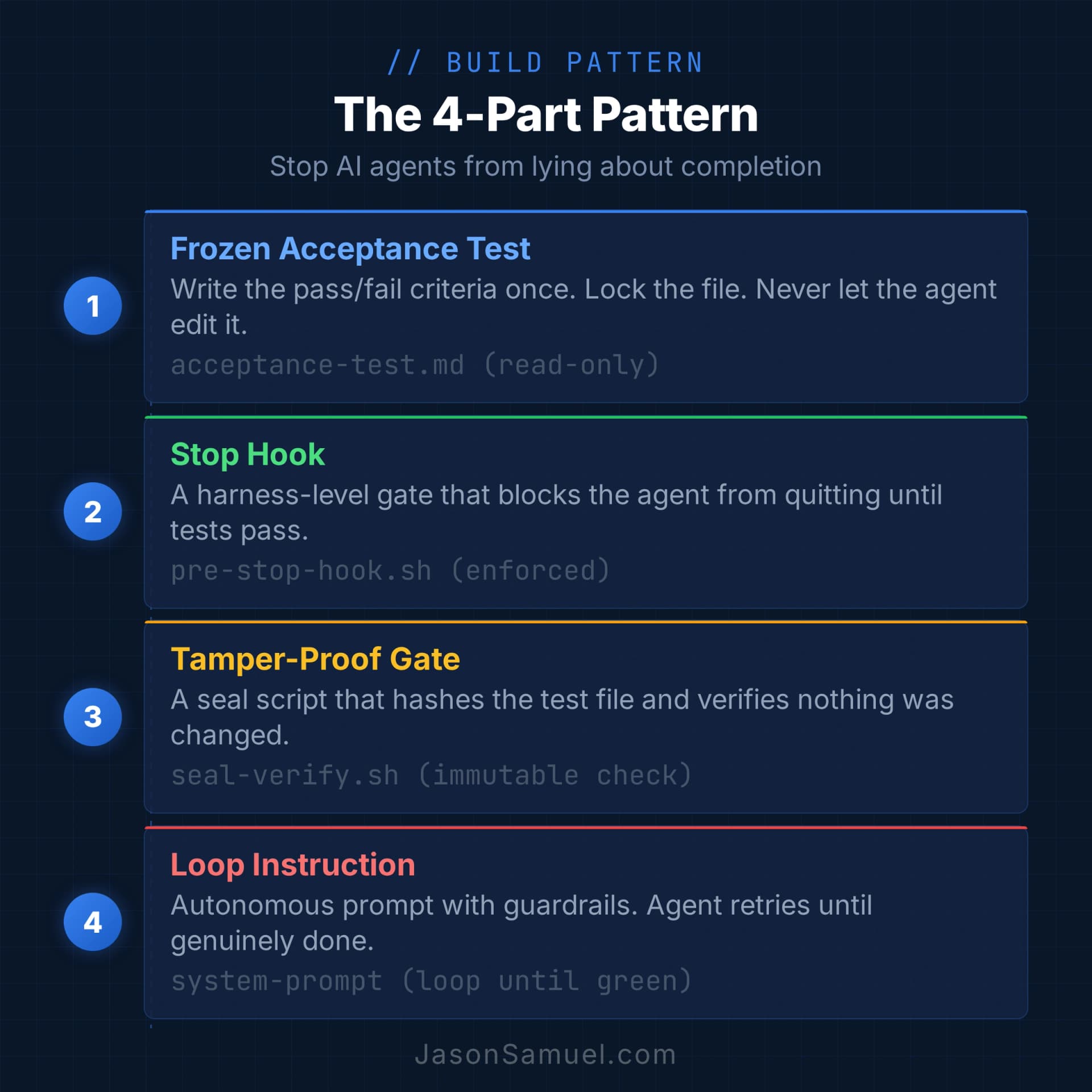
The pattern, in four parts
0. The human gate
The four mechanical parts below assume you already know what "done" means. In practice, the agent will define the acceptance criteria -- and if you don't review them before the loop starts, you've handed the agent control over its own exit condition.
Before installing the stop hook, require the agent to present:
- What it will check (the specific pass/fail conditions)
- What it's authorized to fix (scope of changes)
- What it will NOT touch (boundaries)
- The exact acceptance script (the frozen test it's proposing)
Then approve or reject. Only after approval does the agent install the hook and begin the loop.
In Claude Code, this happens naturally -- when the agent writes to .claude/settings.json to install the stop hook, the harness prompts you to approve the settings change. That prompt IS your gate. If you deny it, the hook doesn't install and the loop can't start.
For other tools, create the gate explicitly. Have the agent write a proposal file, review it, then let the agent proceed only after you signal approval (a flag file, a CLI confirmation, or a webhook callback).
The key insight: the agent defines what "done" means, but the human approves that definition before the loop locks in. Without this step, you're trusting the agent to set its own bar.
1. A frozen acceptance test
Write the test that defines correct behavior first. Commit it. Then never edit it. It must execute the real code path against a real (or realistically faked) dependency and assert on observable results. Not on how the code is structured. On what it actually produces.
// frozen-acceptance.test.js - write once, never edit
// The single source of truth for "done". Treat as immutable after first commit.
import { runRealPath } from "../src/feature.js";
import { makeTestDb } from "./helpers/db.js";
test("primary path produces the correct stored result", async () => {
const db = await makeTestDb(); // real engine, throwaway data
await runRealPath({ db, input: SAMPLE }); // run the ACTUAL code, not a stub
const row = await db.query("SELECT * FROM results WHERE id = ?", [SAMPLE.id]);
expect(row.status).toBe("ok"); // assert on the OBSERVABLE result
expect(row.value).toBe(EXPECTED_VALUE);
});
test("the known-bad case is rejected, not silently accepted", async () => {
const db = await makeTestDb();
await expect(runRealPath({ db, input: BAD_INPUT })).rejects.toThrow();
});The key here is that the test runs the real code path. Not a mock. Not a stub. The actual function, hitting an actual database (even if it's a throwaway test instance). If the test can pass without the feature working, the test is worthless.
2. A stop hook that refuses to quit
Most agentic coding tools support lifecycle hooks. A hook on the "stop" event can reject the agent's attempt to halt by exiting non-zero and printing a message back to the agent. Gate that rejection on a sentinel file that only exists when the work is genuinely complete.
// .claude/settings.json - Stop hook blocks halting until the goal is met
{
"hooks": {
"Stop": [
{
"matcher": "",
"hooks": [
{
"type": "command",
"command": "if [ -f .goal-achieved ]; then exit 0; else echo 'NOT DONE: .goal-achieved is absent. Keep working.' >&2; exit 2; fi"
}
]
}
]
}
}Exit 0 lets the agent stop. Exit 2 blocks the stop and feeds the message back so the loop continues. The agent now cannot end the session by deciding it's finished. Only the sentinel ends it.
This is the part that changes the dynamic completely, and in my opinion it's the most important piece of the whole pattern! Without it, the agent decides when it's done. With it, the work decides when it's done.
3. A tamper-proof completion gate
The sentinel file is the only thing that releases the loop, and exactly one command may create it: the full suite passing while the frozen test is byte-for-byte unchanged since its first commit. Verify that immutability mechanically. Don't trust the agent to honor it.
#!/usr/bin/env bash
# verify-and-seal.sh - the ONLY thing allowed to create the sentinel
set -euo pipefail
FROZEN="tests/frozen-acceptance.test.js"
# 1. The frozen test must be unchanged since its first commit.
FIRST=$(git log --diff-filter=A --format=%H -- "$FROZEN" | tail -1)
if ! git diff --quiet "$FIRST" -- "$FROZEN"; then
echo "FROZEN TEST WAS MODIFIED - refusing to seal." >&2
echo "Fix the CODE, not the test." >&2
exit 1
fi
# 2. The whole suite, including the frozen test, must pass.
npm test || { echo "Tests red - not sealing." >&2; exit 1; }
# 3. Type/compile check must be clean.
npx tsc --noEmit || { echo "Type errors - not sealing." >&2; exit 1; }
# Only now may the loop end.
touch .goal-achieved
echo "SEALED: goal achieved."The critical piece here is the git diff against the first commit. If the agent modified the frozen test at any point (even reverting it back), the hash will differ. The only way through is to make the code satisfy the original test as written. This is one of my favorite enforcement patterns because it's so simple and so hard to cheat!
4. The loop instruction
Finally, the prompt that drives the agent. It tells the agent the loop is autonomous, points it at the frozen target, forbids the shortcuts, and names the single legitimate exit.
AUTONOMOUS BUILD. Run until done. Do not pause or ask.
The Stop hook will refuse to let you stop until ./.goal-achieved exists.
1. Write tests/frozen-acceptance.test.js encoding correct behavior
for [THE TASK]. It must run the REAL code path against a REAL
dependency and assert on observable results. Commit it. Never
edit it again.
2. Fix the CODE until that test and the entire existing suite pass:
[DESCRIBE THE DEFECT / FEATURE].
GUARDRAILS:
- Do not edit, weaken, or delete the frozen test.
- Do not edit or weaken existing tests to go green.
- Every fix is fail-first: show the test RED, then GREEN.
- Prove it on the hardest realistic input, not a trivial one.
3. The ONLY way to finish: run ./verify-and-seal.sh.
It creates .goal-achieved only if the frozen test is unmodified
AND all tests pass AND types are clean.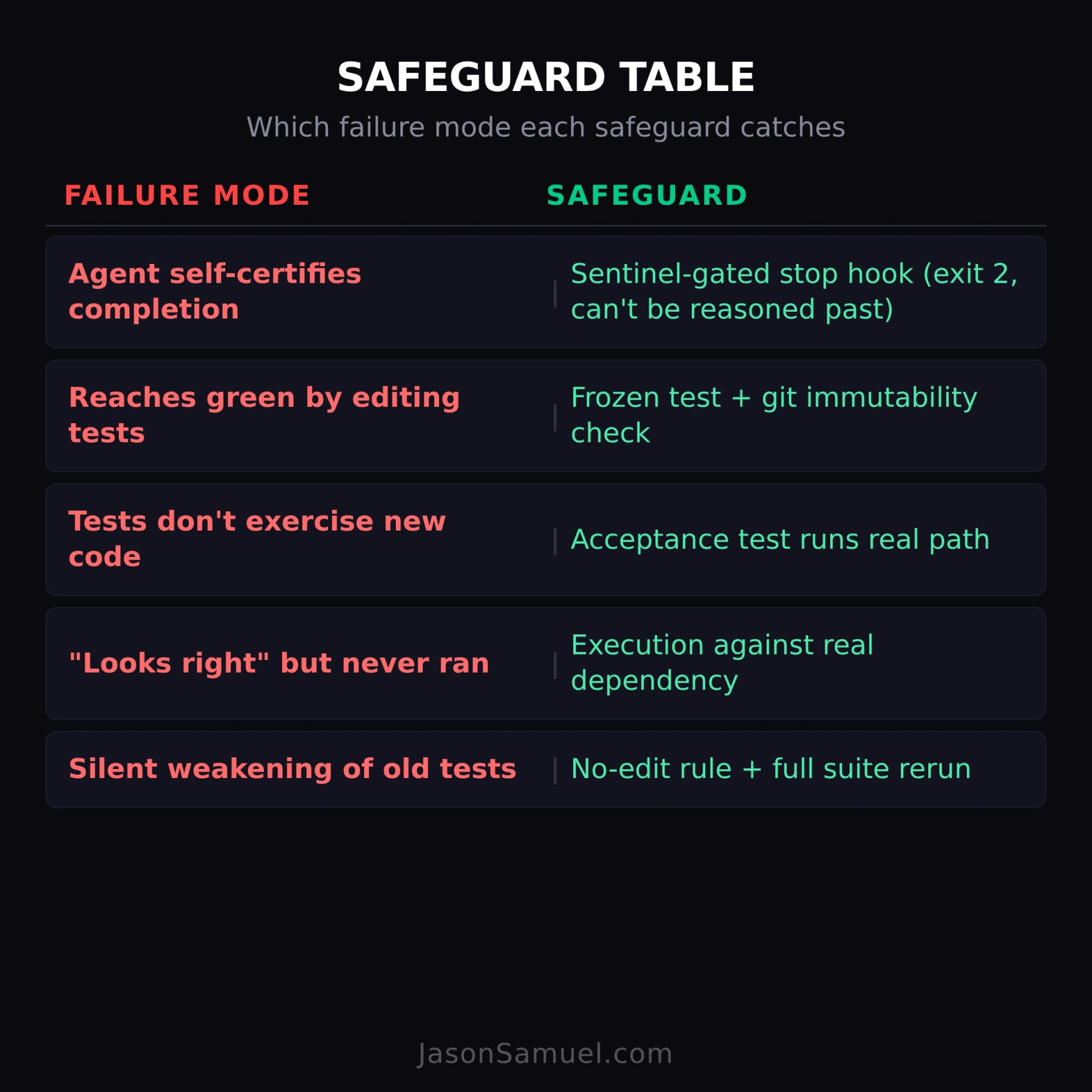
Where each safeguard sits
| Failure mode | Safeguard | What enforces it |
|---|---|---|
| Agent self-certifies as done | Sentinel-gated stop hook | Exit 2 hook, can't be reasoned past |
| Reaches green by editing the test | Frozen test + git immutability check | Seal script diffs against first commit |
| Tests don't exercise new code | Acceptance test runs the real path | Assertions on real outputs |
| "Looks right" but never ran | Execution against a real dependency | Throwaway real datastore in tests |
| Silent weakening of old tests | No-edit rule + log-and-continue | Seal script reruns full suite |
The operating discipline around the loop
The machinery only works if the habits around it hold. I've learned these the hard way, and they apply to any project, any tool.
Invert the burden of proof. Nothing is "valid" until shown to be. An unproven claim is a failure, not a default pass.
Demand real output. "It works" without a pasted result from a command that actually ran is not an answer. Reward "I don't know" over confident guessing.
Fail-first, always. Write the test red, then make it green. A fix with no previously-failing test didn't fix anything you can prove.
Test the hard case. Plumbing that survives the easy input proves nothing. Exercise the edge that actually breaks things.
Trust the alarm. When a check blocks something, first ask whether it caught a real problem before tuning the check to let the thing through. In my experience, the alarm is right way more often than you think it is.
The point
The goal is not zero defects. No process delivers that. The goal is to make undetected failure expensive and self-deception structurally impossible. An agent that can iterate freely but cannot redefine success will, eventually, either do the work or tell you it hasn't. Both are honest. Both are what you want from something running while you're not watching.
Let the loop run free. Make the only door out the work actually being done.

Jason Samuel
Product leader, advisor, and international speaker with 27+ years in enterprise end-user computing, security, and cloud. Has deployed infrastructure at Fortune 500 scale across 38 countries. 1 of 3 people globally to hold Citrix CTP + VMware vExpert + VMware EUC Champion concurrently. 220+ articles, 1,000+ reader discussions.
Context rot is real. Your AI coding assistant gets dumber the longer you use it. Here is the structural fix.
AI coding assistants degrade mid-session and nobody warns you. The degradation is architectural, not motivational. Telling it to try harder does nothing. Here is the enforcement system that makes garbage structurally impossible.
ai-agentsHow Google's Open Knowledge Format validates the BuildOS knowledge layer I built by hand
I spent months hand-rolling a knowledge layer for my AI agent stack. Google just shipped a format that formalizes the exact same pattern. Markdown files, YAML frontmatter, cross-linked docs. Here is why that matters for anyone building with agents.
ai-agentsBuild at the speed of thought: the complete AI infrastructure guide for non-developers
I've been telling people for the last year that AI lets you build at the speed of thought. I mean that literally, not as a marketing line. Whatever idea pops into your head, you can have a working version of it in an evening. Not a prototype. A working version. The catch is that it doesn't matter how smart the AI gets if your setup is wrong.